On the identification of suspicious users on social networks
The article proposes a multi-language approach for supporting the identification of suspicious users on social networks by LEAs and security professionals.
The use of IT technology for the planning and implementation of illegal activities has been gaining ground in recent years. Nowadays, through the web and the social media, it is possible not only to divulge advertising for the disclosure of illicit activities, but also to take action that in the past needed to have people in place and at the moment the activity took place. In fact, this phenomenon allows criminals to be less exposed to the risk of being discovered. Furthermore, the technology tends to encourage international collaborations, which makes the process of identifying illegal activities even more complex because of the lack of adequate tools that can operate effectively by considering multi-cultural aspects. Consequently, this evolving phenomenon towards cyber-crime requires new models and analysis techniques to address these challenges.
In this context, the article proposes an approach based on a multi-language model that aims to support the identification of suspicious users on social networks. It exploits the effectiveness of web translation services along with specific stand-alone libraries for normalizing user profiles in a common language. In addition, different text analysis techniques are combined for supporting the user profiles evaluation. The proposed approach is exemplified through a case study by analysing Twitter users profile by showing step by step the overall process and related results.
The reference process
This document aims to provide an overview of the proposed multi-language approach which is centered on 4 main phases: User Profile Acquisition, Language Profile Normalization, Multi Criteria Evaluation and Results Assessment as it is shown in Figure 1.
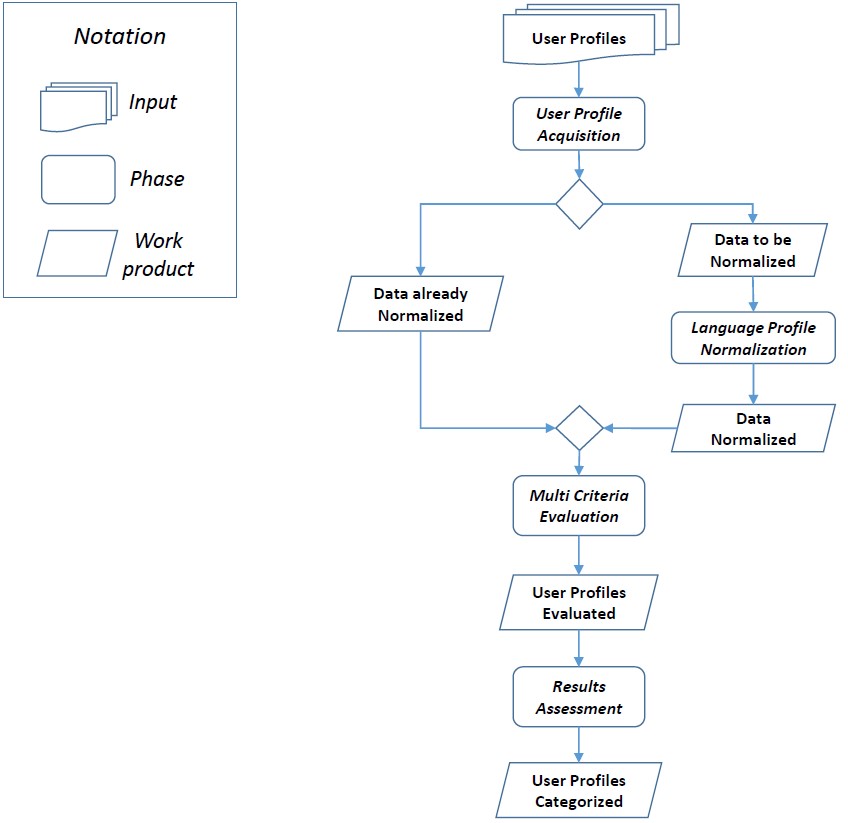
Fig. 1. The Reference Process
In the following subsection a few details about each phase are provided.
User Profile Acquisition phase
In this phase online user profiles, which are going to be analyzed, are collected. This phase can be executed in two distinct modalities: automatic profiles acquisition or user-driven profile acquisition. When the automatic acquisition mode is adopted the online user profiles are selected automatically based on specific well defined techniques or rules based on different languages. The main advantage of this modality relies in the ability of collecting and analyzing a huge amount of profiles. When the user-driven profile acquisition mode is adopted, the user decides which profile has to be analyzed. The choice is not based on any specific automatic techniques or rules, but it is rather directly provided by the user. This mode is particularly useful, when a specific user profile, that might look suspicious, is discovered by another user and it has to be added among the potential suspicious profiles. This phase ends by producing a set of Potential Suspicious User Profile (in different language).
Language Profile Normalization phase
In this phase, a language analysis of each acquired profile takes place by transforming all the necessary information of each user profile in a common reference language (i.e. in English). First of all, based on more specific meta-data such as the location, nationality and especially the textual information, a first classification is done among English and Non-English profiles. If a user profile is already in English, then there is no need to perform such transformation, whereas if the profile is a Non-English one, then the profile normalization is performed. In particular, since it is not easy to translate sentences and concepts from one language to another one by being sure to keep the meaning unchanged, an election approach, based on a similarity criterion is adopted. In particular, a sentence/concept is translated using multiple service which generate multiple candidate translation. The best translation will be the candidate with the highest degree of similarity with the others. This phase ends by producing a set of user tweets normalized in English language.
Multi Criteria Evaluation phase
This phase takes in input the normalized user tweets and it takes care to process the necessary meta-data and related values on the basis of specific evaluation criteria. In particular, the classification module or technique to classify user profiles as suspicious or not, is based on different indicators. These different indexes and metrics are used and combined to evaluate the level of suspiciousness of a user profile of a social network.
Results Assessment phase
This is the last phase of the proposed approach. It takes in input the information gathered from the multi criteria evaluation phase and it aims at providing information on the level of suspiciousness of a specific user. The assessment can be automatically performed, by defining specific threshold values for each adopted evaluation criteria, or it can be used as decision support system when the domain expert is in charge to provide the assessment of a user profile.
The activity highlighted in this article dealt with cyber-crime activities and, in particular, it has faced with the identification of suspicious users on social networks. A multi-language approach centered on 4 main phases (User Profile Acquisition, Language Profile Normalization, Multi Criteria Evaluation and Results Assessment) has been defined. A first implementation has been experimented for the analysis of Twitter users. Specifically, three main online translation services (i.e. Google, Bing and Yandex), to automate the translation process of tweets written in languages different from English, have been used; whereas an algorithm for the selection of the best translation, based on similarity criteria, has been defined and implemented. Then specific evaluation criteria have been combined along with different analysis techniques (i.e. Bag-of-Words, WordNet, N-gram and TF-IDF) for supporting the assessment of user profiles on the basis the tweets generated.
Note: This article is based on the following publication: A. Tundis and M. Mühlhäuser, “A multi-language approach towards the identification of suspicious users on social networks,” The International Carnahan Conference on Security Technology (ICCST), Madrid, 2017, pp. 1-6. doi: 10.1109/CCST.2017.8167794)
Author
Andrea Tundis, Technische Universität Darmstadt
Links
http://ieeexplore.ieee.org/document/8167794